





谷歌于去年年底发布了一个精简型的机器语义分析项目:飞马(PEGASUS):预先机器学习及训练后的自动文章摘要项目。近期这个项目迎来的新的版本,这个小型项目可以非常精准的自动提取出文章中的摘要,并且只用一千个训练模型就可以生成媲美人类的摘要内容。
当对包括文本摘要在内的下游NLP任务进行微调时,最近针对大型文本语料库进行自我学习的目标的预训练工作已显示出巨大的成功。
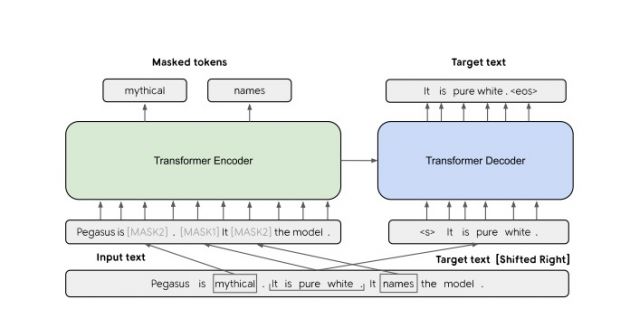
但是,尚未探讨为抽象文本摘要量身定制的预训练目标。此外,缺乏跨不同领域的系统评估。在这项工作中,我们提出了在大规模文本语料库上使用新的自我训练目标对基于大型编解码器模型进行预训练的方法。在PEGASUS中,重要句子从输入文档中删除/掩盖,并作为其余句子的一个输出序列一起生成,类似于摘录摘要。
我们在涉及新闻,科学,故事,说明,电子邮件,专利和立法法案的12个下游汇总任务中评估了最佳PEGASUS模型。
实验表明,在通过ROUGE分数衡量的所有12个下游数据集上,它均达到了最先进的性能。我们的模型还显示了在低资源汇总方面的令人惊讶的性能,超过了仅使用1000个学习后的6个数据集上的最新结果。
最后,我们使用人工评估验证了我们的结果,并表明我们的模型摘要可在多个数据集上实现人工表现。
附件:如何部署一个自动摘要的环境
项目地址:https://github.com/google-research/pegasus
请先创建一个项目并创建一个实例
在github上克隆库并安装要求。
按照说明安装gsutil。
下载“混合与动态”模型的vocab,经过预训练和微调的检查点。
对现有数据集进行微调aeslc。
评估经过微调的数据集。
请注意,上面的示例使用的是单个GPU,因此batch_size远小于本文报告的结果。
支持两种类型的数据集格式:TensorFlow数据集(TFDS)或TFRecords。
本教程说明如何在TFDS中添加新的数据集。(希望对微调数据集进行监督,请supervised_keys在数据集信息中提供 )。
Tfrecords格式要求每个记录都是的tf示例{"inputs":tf.string, "targets":tf.string}。
例如,如果您注册了一个new_tfds_dataset用于训练和评估的TFDS数据集,并且有一些文件名为tfrecord格式new_dataset_files.tfrecord*用于测试,则可以在中注册它们/pegasus/params/public_params.py。
评估结果可在中找到mode_dir。自动为每个评估点计算汇总指标。
可以在以下几种类型的输出文件中找到 model_dir
(在C4或任何其他语料库上)的预训练需要定制构建的tensorflow,其中包括进行实时解析的操作,这些操作将原始文本文档处理为模型输入并指定ID。有关详细信息,请参阅pegasus / ops / pretrain_parsing_ops.cc和pegasus / data / parsers.py。

